How to Build a Data Agent: The OpenAI Blueprint

Two engineers at OpenAI spent three months building an internal data agent. Seventy percent of its code was written by AI. Today, that tool handles data queries for over 3,500 employees across finance, engineering, sales, and research, turning what used to be hours of SQL work into a plain-English question typed into Slack. The core lesson for business owners isn't about OpenAI's engineering talent. It's that the barrier to building a functional AI data agent has dropped far enough that a small team, working with modern tools, can deploy something that genuinely changes how an organization accesses and uses its own information.
Key Takeaways:
- OpenAI's internal data agent was built by two engineers in three months, with AI writing 70% of the code, a template that scales down to smaller organizations
- SMEs can deploy AI data agents without large technical teams by using low-code platforms or working with implementation partners who handle the configuration
- Off-the-shelf platforms cost $99 to $1,500/month and suit most SMEs; custom builds run $20,000 to $500,000 but offer better long-term economics for complex, high-volume use cases
- The business case centers on time recovery: according to vendor-reported data from Stratpilot, AI tools save 58% of SME users more than 20 hours per month
Table of Contents
- What OpenAI's Internal Data Agent Actually Does
- How Do You Build a Data Agent Without a Large Engineering Team?
- Off-the-Shelf Platforms vs. Custom Builds: A Practical Comparison
- What the OpenAI Case Reveals About SME Readiness
- How Implementation Partners Close the Gap Between Pilot and Production
- What ROI Can SMEs Expect From an AI Data Agent?
- How SMEs Can Start Without a Two-Engineer Team
- A Realistic Three-Month Starting Plan
- What "Anyone Can Replicate This" Actually Means
What OpenAI's Internal Data Agent Actually Does
OpenAI's data agent is a natural language interface that sits on top of the company's internal data infrastructure, roughly 600 petabytes of datasets, and lets employees ask business questions in plain English instead of writing SQL queries. According to Atlan's analysis of the deployment, the agent reduced time-to-insight from days to minutes for tasks like comparing revenue across geographies, evaluating product launches, and assessing business health metrics.

The system uses six context layers: table usage patterns, annotations, code analysis, institutional knowledge, memory from prior queries, and live validation. When a query returns zero rows because of a bad join, the agent catches it and self-corrects. It also retains conversational context, so analysts can iterate on a question rather than starting from scratch each time.
Critically, the agent enforces data permissions that mirror the organization's existing access controls. A finance analyst sees finance data. An engineer sees engineering data. This isn't a cosmetic feature, it's what makes the tool deployable across an organization without creating data governance problems.
The contract data agent, built separately for finance and legal use cases, automates contract review to support business growth without requiring proportional headcount increases. Both agents were built using GPT-4 and Codex, with a memory system layered on top.
How Do You Build a Data Agent Without a Large Engineering Team?
Building a data agent follows a more structured path than most business owners expect. The OpenAI case is instructive not because it's technically exotic, but because it illustrates a clear sequence: identify the bottleneck, connect to the data, add a natural language interface, validate outputs, and enforce access controls.
For most SMEs, the sequence looks like this:
- Identify one high-friction data workflow, the question that takes hours to answer today (revenue by region, customer cohort retention, inventory by SKU)
- Audit your data sources, which databases, spreadsheets, or SaaS platforms hold the relevant data, and whether they have accessible APIs or connectors
- Choose a platform layer, either a low-code tool that handles the agent framework, or a pre-built integration if your data lives in a platform like Salesforce or HubSpot
- Define the query scope, what questions the agent should answer, and what data it should never touch
- Set access controls, mirror your existing permission structure so the agent doesn't expose data across organizational boundaries
- Test with real queries, validate outputs against known answers before rolling out broadly
- Build in a feedback loop, let users flag incorrect answers so the system learns from corrections
The OpenAI team built its memory system specifically to capture corrections and institutional knowledge over time. That compounding improvement is what separates a useful agent from one that gets abandoned after the novelty wears off.
Off-the-Shelf Platforms vs. Custom Builds: A Practical Comparison
The build-vs-buy question is where most SME decisions stall. The honest answer depends on data complexity, query volume, and how differentiated the use case is.
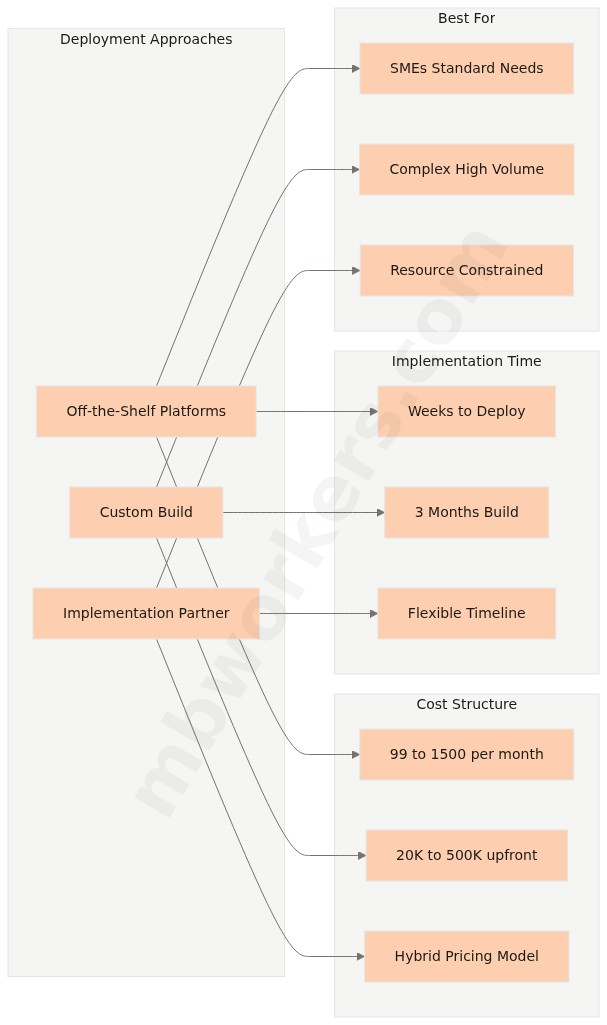
According to Scalevise's cost analysis, off-the-shelf platforms run $99 to $1,500 per month, while custom AI agent development ranges from $20,000 to $500,000 upfront. The three-year economics typically favor custom builds for high-volume, complex deployments, but off-the-shelf solutions are faster to deploy and carry lower risk for organizations testing the concept.
| Factor | Off-the-Shelf Platform | Custom Build |
|---|---|---|
| Upfront cost | $1,000 to $100,000 | $20,000 to $500,000 |
| Monthly cost | $99 to $1,500/month | Minimal after build |
| Time to deploy | Days to weeks | 3 to 6 months |
| Customization | Limited to platform features | Full control |
| Data integration | Pre-built connectors | Custom connectors required |
| Long-term economics | Costs rise 20 to 30% at renewal | Scales efficiently |
| Best for | Standard use cases, limited data complexity | Differentiated workflows, high query volume |
For most SMEs, the starting point is a platform layer. Microsoft 365 Copilot connects to Excel, Teams, and SharePoint data. Salesforce Agentforce 360 works across CRM data without custom development. Google Workspace AI integrates directly into Sheets and Docs. These tools don't require a data engineering team to configure, they require someone who understands the business questions worth answering.
The gap between "we have the tool" and "the tool answers our actual questions accurately" is where implementation expertise matters. That gap is also where most off-the-shelf deployments underdeliver.
What the OpenAI Case Reveals About SME Readiness
The two-engineer, three-month timeline at OpenAI shows that the real constraint is organizational, not technical: knowing which problem to solve and connecting the agent to trustworthy data. Those are operational questions, not engineering ones.
According to the OECD's 2025 report on AI adoption by SMEs, adoption rates among small firms reached 55 to 68% in 2025, but most deployments remain in experimentation rather than full operational integration. The gap between running a pilot and running a production system that employees rely on daily is where most SME AI projects stall.
Three patterns explain why pilots fail to scale:
Data quality problems surface late. An agent is only as useful as the data it queries. If revenue data lives in three different spreadsheets with inconsistent naming conventions, a natural language interface won't fix that, it will surface the inconsistency at scale. Data cleanup is unglamorous work, but it determines whether the agent produces trustworthy outputs.
Scope creep kills momentum. The OpenAI team started with a specific use case: answering business questions from structured internal data. SMEs that try to build an agent that answers everything tend to build one that answers nothing reliably. A focused agent that handles five question types accurately is more valuable than a broad one that handles fifty question types inconsistently.
Access control gets deprioritized. Giving an AI agent access to all company data for convenience creates governance problems that surface later, often badly. Defining data boundaries before deployment, not after, is the decision that determines whether the tool can be trusted at scale.
How Implementation Partners Close the Gap Between Pilot and Production
These aren't reasons to avoid building a data agent. They're the specific problems to solve before launch. For SMEs without internal technical resources, an implementation partner's value isn't writing code, it's structuring the deployment to avoid these failure modes from the start: cleaning the right data first, configuring access controls before go-live, and scoping the agent tightly enough that early outputs are trustworthy.
Organizations that have navigated multiple deployments bring pattern recognition that compresses the learning curve significantly. Knowing which data quality issues to fix first, which platform connectors are reliable, and how to structure permissions for a specific organizational structure is what separates a pilot that scales from one that quietly gets abandoned. The AI readiness assessment process is worth working through before committing to a platform or a build approach, because the organizational factors matter as much as the technical ones.
What ROI Can SMEs Expect From an AI Data Agent?
The business case for a data agent isn't abstract. It's recoverable hours and faster decisions.
According to vendor-reported data from Stratpilot, 58% of SME AI users recover more than 20 hours per month from automation. For data-intensive workflows, financial reporting, sales performance analysis, inventory tracking, the time savings concentrate in the people who currently spend significant portions of their week pulling and formatting data rather than analyzing it.
The more durable ROI comes from decision speed. When a finance analyst can answer a revenue question in ten minutes instead of three hours, the business makes faster decisions with more current data. That compounding effect is harder to quantify in a spreadsheet but is what OpenAI's team highlighted as the primary value: the agent enables questions that previously weren't worth asking because the cost of answering them was too high.
For SMEs evaluating the investment, the relevant comparison isn't "cost of the agent vs. zero." It's "cost of the agent vs. the loaded cost of the analyst hours currently spent on data retrieval, plus the value of decisions made faster." On that framing, even a modest deployment that saves a senior analyst 15 hours per month pays back quickly. You can explore how AI agents reduce operational costs in more detail if you want to model the numbers for your own context.
How SMEs Can Start Without a Two-Engineer Team
OpenAI had two engineers. Most SMEs won't allocate that. The practical question is what a realistic starting point looks like for a business without a dedicated technical team.
The most accessible entry points in 2025 to 2026 are platforms that embed AI query capabilities into tools SMEs already use. According to AWS's SMB AI resource guide, console-guided workflows and pay-as-you-go services let small businesses implement AI without dedicated data scientists. The configuration work is real, but it doesn't require writing code.
For businesses with data spread across multiple systems, a CRM, an accounting platform, a project management tool, the integration layer is the harder problem. No-code platforms like those reviewed on Konverso's 2026 platform comparison now support direct connections to enterprise data sources with security compliance built in, which removes the technical barrier that would have required a developer two years ago. If your systems include older infrastructure, the guide to integrating no-code workflows with legacy systems covers the specific connection challenges worth planning for.
A Realistic Three-Month Starting Plan
The practical path for most SMEs follows a phased approach that mirrors what OpenAI actually did, build for one problem, validate it, then expand.
- Month 1: Identify the one data question that takes the most time to answer today. Audit where that data lives and whether it's clean enough to query reliably.
- Month 2: Deploy a platform-level tool (Copilot, Agentforce, or a no-code agent builder) against that single data source. Test with real queries. Fix the data quality issues that surface.
- Month 3: Expand to a second use case or a second data source, using what you learned from the first deployment.
The AI agent projects framework for 2026 covers how to structure that sequencing in more detail.
The other option is working with an implementation partner who has already navigated these decisions across multiple deployments. The value isn't technical labor, it's pattern recognition. Knowing which data quality issues to fix first, which platform connectors are reliable, and how to structure access controls for an organization's specific structure compresses the learning curve significantly. For SMEs without the time to run a three-month internal experiment, that compression is the actual product.
What "Anyone Can Replicate This" Actually Means
OpenAI's public framing, that any company can build what its two engineers built, is accurate but requires translation. The tools exist. The models are accessible. The platforms that abstract away the infrastructure complexity are mature enough to use without deep technical expertise.
What it actually means for SMEs: the engineering barrier is no longer the constraint. The constraint is organizational, knowing which problem to solve, having data that's clean enough to query, and maintaining the discipline to start small rather than trying to build everything at once.
The PwC 2025 AI Predictions report notes that organizations seeing the strongest AI ROI are those treating AI deployment as an operational discipline rather than a technology project. That distinction matters. A technology project succeeds when it's built. An operational discipline succeeds when it changes how people work every day.
OpenAI's finance analyst now types a question into Slack and gets a chart. That's not a technology outcome. It's a workflow outcome. The planning should start with a specific workflow the business wants to change and a definition of what success looks like six months after deployment, not with the technology.
Frequently Asked Questions
How long does it take to build an AI data agent?
OpenAI's internal data agent took two engineers three months to build, with AI writing 70% of the code. For SMEs using off-the-shelf platforms, deployment can be significantly faster, often weeks rather than months, depending on data complexity and access controls.
How much does it cost to build a data agent?
Off-the-shelf platforms typically run $99 to $1,500 per month and suit most SMEs. Custom builds range from $20,000 to $500,000 and make more sense for complex, high-volume use cases where long-term economics justify the upfront investment.
Do you need a technical team to deploy an AI data agent?
Not necessarily. SMEs can use low-code platforms or work with implementation partners who handle configuration. OpenAI's own build required just two engineers, and modern tooling has lowered the bar further since then.
What business problems does an AI data agent solve?
A data agent lets employees ask business questions in plain English instead of writing SQL queries. According to vendor-reported data from Stratpilot, AI tools save 58% of SME users more than 20 hours per month, primarily by cutting time-to-insight on routine data tasks.
Geschreven door


AI Agent Projects in 2026: 5 Things to Do Now
70–90% of AI agent projects fail before they scale. Here are 5 concrete actions SMEs can take now to be in the minority that delivers results in 2026.
Lees artikel
10 KPIs for AI-Driven Training Programs
Learn the essential KPIs for measuring the success of AI-driven training programs and how they can enhance employee performance and business outcomes.
Lees artikel
Integrating No-Code Workflows with Legacy Systems
Learn how integrating no-code platforms with legacy systems can enhance efficiency, cut costs, and streamline workflows without replacing existing technologies.
Lees artikel
